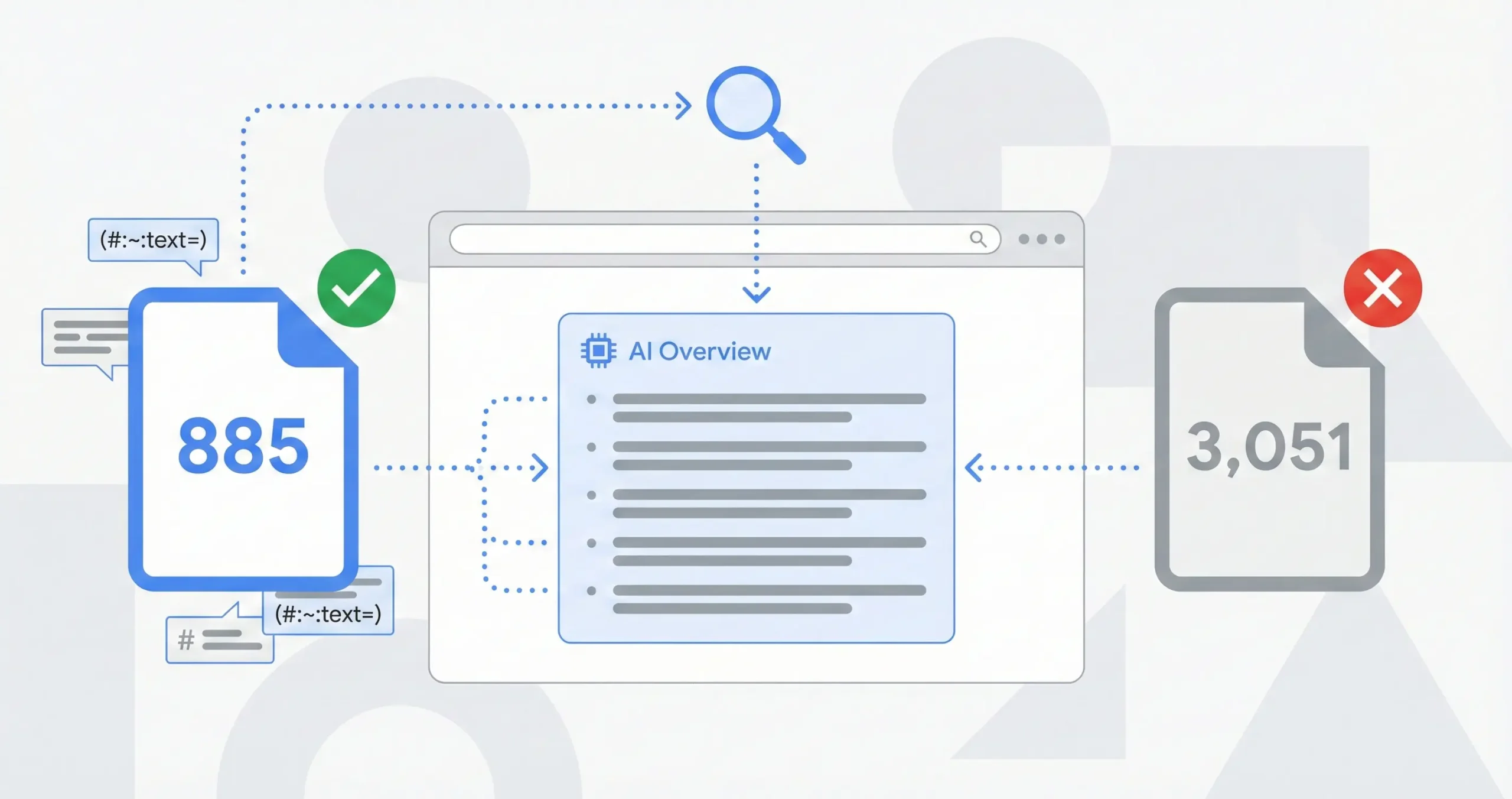
TL;DR
I reverse engineered the source code of Google’s AI Overview for “wrongful death lawyers orlando” and found that getting cited has nothing to do with word count, schema markup, reviews, or traditional SEO metrics. The AI extracts unique, quotable differentiators from your first two paragraphs. A firm with 885 words got cited while a firm with 3,051 words, 624 reviews, and 7+ schema types got skipped entirely.
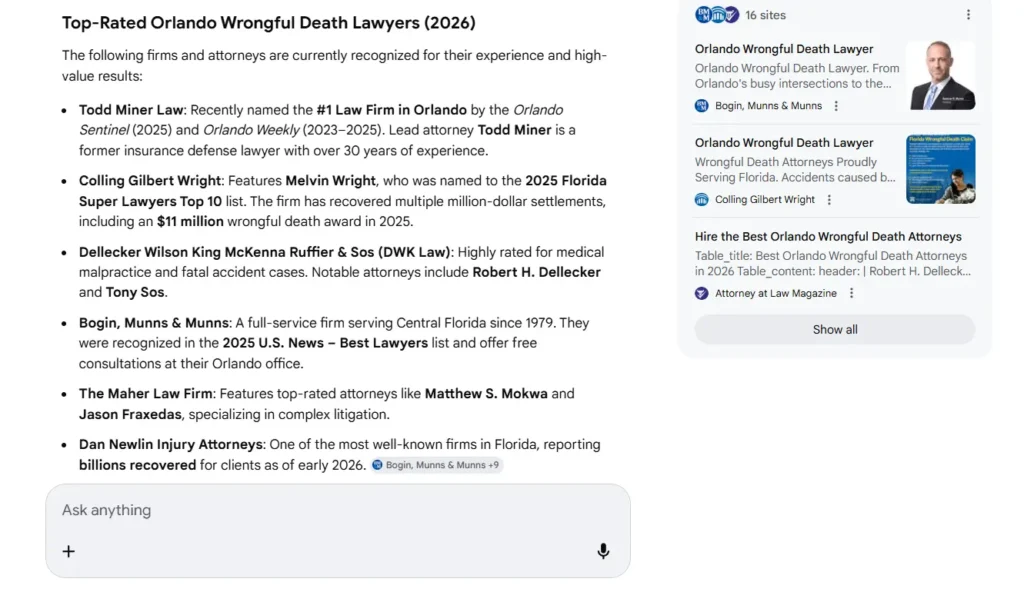
So I searched “wrongful death lawyers orlando” from Brandon, Florida on January 29th and when the AI Overview loaded I counted 15 law firms in the bullet list and some of them I recognized as major operations with thousands of words of content and hundreds of reviews and some of them had basic 900 word pages with almost no backlinks, and the thing that made me pull open Chrome DevTools instead of just moving on was that the firms with the strongest traditional SEO weren’t necessarily the ones getting cited, and I wanted to know why so I spent the next several hours going through the actual source code element by element.
And I don’t mean I skimmed the page; I mean I extracted over 1,500 data attributes, identified 438 JavaScript controllers, decoded the text fragment URLs that show exactly which sentence on each page Google pulled from, and mapped the entire rendering pipeline from initial placeholder to completed AI response. I recently analyzed how Google’s AI treats paid directory listings like FindLaw and Justia where firms are spending $102,000 a year on placements that feed the same AI system, and what I found in that analysis led me to look deeper at how the citation mechanism actually works which is what this post is about.
885
Words on the page that got cited. The page that didn’t get cited had 3,051 words.
And that number is the entire thesis of what I found because Todd Miner’s page is 885 words with 2 schema types and a relatively simple structure and it got cited in the AI Overview, and Bogin Munns has a 3,051 word page with 7+ schema types and 144 internal links and 624 reviews at 4.8 stars and an extensive FAQ section and case results in the millions and Google’s AI didn’t cite them at all, and the reason has nothing to do with authority or word count or schema or reviews. I wrote about how AI Overviews are affecting law firm traffic separately because the click data is its own problem but for this post I want to focus on the citation mechanism itself.
How Google’s AI actually builds the citation list
Step 1: Standard SEO match
The AI finds pages matching the query using normal ranking signals; links, keywords, authority, the usual stuff that everybody already optimizes for.
Step 2: First paragraph scan
The AI reads the first two paragraphs of main body content looking for passages that answer one question; “what makes THIS firm different from the other fourteen?”
Step 3: Text fragment extraction
When it finds a unique differentiator, it creates a text fragment URL (#:~:text=) that deep-links to that exact passage. I found 12 of these in the source code for this one query.
Step 4: Diversity filter
The AI selects firms with different value propositions so the Overview shows variety; one for “50 years experience,” another for “bilingual services,” another for “expert investigators.” If your differentiator overlaps with a stronger firm’s, you get dropped.
Step 5: Bullet generation
Each firm gets one bullet formatted as “[Firm Name]: [paraphrased unique differentiator].” The whole thing renders in 971 milliseconds according to the timing metrics I pulled from the gen_204 beacon.
And the reason I know this is the process is because of the text fragment URLs which are like a receipt showing you exactly what the AI shoplifted from each page, and when I matched every fragment back to its source page the pattern was undeniable; every cited firm had a specific, unique, quotable sentence in the first two paragraphs and every skipped firm either had generic language or buried their differentiator somewhere the AI couldn’t find it.
WHAT THE AI EXTRACTED VS. WHAT IT OUTPUT
Meldon Law
Page text: “we have spent more than 50 years standing beside Florida families”
AI output: “Specializes in representing families for over 50 years”
Legally Pink Law
Page text: “we can call upon expert consultants and witnesses; from medical professionals to private investigators”
AI output: “Utilizes expert consultants and investigators to prove negligence”
Sherris Legal
Page text: mentions “bilingual” and “family-run”
AI output: “A family-run firm providing bilingual (English/Spanish) services”
Todd Miner
Page text: “we understand your pain and frustration” + visible case results ($1.35M, $1.25M)
AI output: “Known for helping families recover compensation for negligent deaths”
Payne Law
Page text: “Contact Payne Law for Your…path to justice and peace”
AI output: “Focuses on insurance claims and offers dedicated representation”
1 Text fragments extracted from Chrome DevTools source inspection of AI Overview container, January 29, 2026. Each fragment uses the #:~:text= URL format to deep-link to the exact passage cited.
The AI needs to write “[Firm Name]: [something interesting about them].” If your page doesn’t give it something interesting, you’re invisible to AI Overview.
WHY STRONG SEO DIDN’T SAVE BOGIN MUNNS
Not cited: Bogin Munns
3,051 words of content, 7+ schema types, 624 reviews at 4.8 stars, case results in the millions, 144 internal links, multiple office locations. By every traditional SEO metric this should be the top cited firm on the page.
The problem
Their hero text says “Our Orlando wrongful death lawyers are dedicated to helping surviving family members secure the compensation they deserve” which is what every single wrongful death page in the country says and the AI can’t pull a differentiator from it.
Why Todd Miner was cited instead
885 words, 2 schema types, simpler structure, but emotional hero text with personality plus case results ($1.35M, $1.25M, $500K, $375K) displayed prominently. The AI had something unique to extract.
3,051
Words (Bogin Munns, NOT cited)
→
885
Words (Todd Miner, CITED)
What I found in the source code that nobody else is publishing
The AI Overview container sits inside a div with ID eKIzJc and carries data-aim=”1″ marking it as AI powered content and data-mlro which is an encoded machine learning response object and data-mrc which is the model response config, and the source carousel uses a JS controller called qwbW4b that manages the source cards with favicons loaded from a CDN endpoint that includes client=AIM in the parameters confirming it’s the AI Mode pipeline.
And the timing data from the gen_204 beacon shows the full AI content loads at sirt-aimc.540 which is 540 milliseconds for the main content and sirt-aimfl.971 for the complete feature load, meaning the AI is generating and sourcing all 15 firm bullet points with text fragment citations in under a second, and this is the kind of detail that tells you this isn’t some slow deliberative process; it’s a fast extraction pipeline that needs pre formatted quotable content sitting exactly where it expects to find it.
2 Complete source analysis: 91 scripts totaling ~500KB of data extracted from the AI Overview section. 165 data-ved tracking codes, 84 hveid event IDs, 680 data-processed markers identified.

WHAT DIDN’T MATTER FOR GETTING CITED
7+ schema types including FAQ, Product, Article, and LegalService
Bogin Munns had more structured data markup than any other page in the results and it didn’t help because schema tells Google what type of content the page contains but doesn’t provide quotable differentiators. Schema says “this is a legal service page.” It doesn’t say “why this legal service is different from the other fourteen.” The AI needs the second thing and schema can’t give it.
624 reviews at 4.8 stars
Reviews help with Google Business Profile rankings and local pack results but the AI Overview citation mechanism extracts from page content not review signals. The AI Overview and Google Business Profile are different systems looking at different things, and a perfect review score doesn’t feed the text fragment extraction pipeline at all based on what I saw in this analysis.
3,051 words of content
More content gives the AI more to scan but if none of it contains a unique quotable differentiator then more words just means more generic text the AI has to wade through without finding what it needs. The 885 word page won because word one through sentence three had exactly what the AI was looking for, and the 3,051 word page lost because paragraphs one through thirty all said the same thing every other firm says.
144 internal links and extensive site architecture
Internal linking strength helps the page rank in traditional organic results which is step one of the citation process, so it’s not useless; it gets you in the candidate pool. But once you’re in the candidate pool the citation decision comes down to what’s in your first two paragraphs, and links don’t affect that. You need both; the links to get found and the differentiator to get cited.
Case results in the millions ($3M, $2.9M settlements)
Case results actually DO matter when they’re prominently displayed in the hero section of the page; Todd Miner had theirs visible and got cited. But Bogin Munns had their results buried deeper in the page where the text fragment extraction either didn’t reach them or couldn’t connect them to a quotable sentence about the firm’s identity. Placement matters as much as the numbers themselves.
And the thing that keeps coming back to me after going through all of this is that most law firm websites are optimized for the old system where authority and volume and technical SEO signals determined rankings, but the AI Overview is running a different game on top of the same ranking results where the decision to cite you comes down to one thing the old system never cared about; whether your first two paragraphs give the AI something unique and quotable to say about you. Traditional law firm SEO gets you into the candidate pool but the citation decision happens after that and most agencies aren’t optimizing for it yet, and those are two different things now.
Rewriting your first two paragraphs
And the fix is actually the simplest part of this whole analysis because you don’t need to rebuild your page or add more schema or get more reviews; you need to put one or two sentences in the first two paragraphs that give the AI something quotable and unique, and I can give you the exact categories of differentiators that worked for the firms that got cited because I mapped all of them. If you haven’t already read my breakdown on getting your law firm into AI Overviews the foundation starts there and this post builds on top of it with the source code data.
Specific year count: “50 years” not “decades of experience”
Named methodology: “expert consultants and witnesses from medical professionals to private investigators”
Language capability: “bilingual English and Spanish services”
Firm structure: “family-run firm” or “boutique practice”
Named attorney + specialty: “Attorney [Name] has handled [number] wrongful death cases in [County]”
Visible case results: Dollar amounts in the hero section, not buried below the fold
Geographic specificity: “exclusively serves Central Florida families” not “serves clients nationwide”
And the placement matters because the text fragment extraction pulls from main body content in the first two paragraphs specifically; not from FAQ accordions, not from sidebar widgets, not from footer text, not from schema markup. This is part of what I call generative engine optimization for law firms which is a different discipline from traditional SEO and the distinction matters because the ranking signals and the citation signals are two different systems now. The sentence needs to be in plain HTML paragraph text near the top of the page where the AI scans first, and honestly that’s the part I think most people are going to get wrong because the instinct is to bury differentiators inside testimonials or case study sections further down the page where the extraction doesn’t reach, or at least didn’t reach in any of the pages I analyzed for this query. And if you’re wondering what the first year of law firm SEO actually looks like month by month I mapped that out separately because the timeline matters for setting expectations on when these changes start compounding.
And the reason this matters beyond visibility is that studies are showing AI search traffic that converts at 6x the rate of traditional organic which means the firms getting cited aren’t just getting seen; they’re getting the highest converting traffic Google has ever produced. If you want to know whether your practice area pages have a quotable differentiator in the first two paragraphs or if the AI is going to skip you the same way it skipped a firm with 624 reviews and 3,051 words of content, that’s part of what we do in our AI search optimization work and I can run this same analysis on your pages and tell you exactly what to change and where to put it, and if your pages are already set up correctly I’ll tell you that too because I don’t need the work that badly.
Analysis conducted January 29, 2026 from Brandon, Florida. Query: “wrongful death lawyers orlando.” Total data extracted: approximately 500KB of structured information from AI Overview section including DOM structure, JavaScript controllers, text fragment URLs, embedded JSON data structures, and timing metrics. Findings based on comparison of 6+ cited and non-cited pages for this single query; additional queries should be tested to confirm patterns across practice areas and markets.



